属性配置 - 专家模式
专家模式通过 json 编辑的方式可以修改所有配置项。
专家模式的参数
专家模式相较于简单模式多出来的配置项有:
| 字段 | 可选值 | 解释 | 默认 |
|---|---|---|---|
| is_observation | true/false | 该属性是否是一个观测值/余额值。对于 observation 的详细解释在下文 | false |
| is_supplementary | true/false | 学习系统完全忽略该字段里面储存的值,该字段仅用作查资料的作用。 | |
| is_count | true/false | 当提问者问题是【schema名称+数量/量】的时候,默认产生的sql为count(1) from schema。该配置项可以让count(1)改为sum(此字段)`。 | false |
| auto_syno | true/false | 对该字段里面的值做模糊匹配学习。例如:一个名称类型的字段,里面储存了【帅气牛仔裤】这个词,那在开启 auto_syno 前,搜索帅气将搜索不到此数据。开启了之后就可以通过帅气搜索到。注意:这个选项开启后将会造成出现大量同义词。可能会造成问答系统混乱,慎用。 | false |
| ui | {} | ui 字段里面是一个 json object,里面定义了各种和显示有关的配置。ui 字段支持的配置项如下文所示。 | {} |
| impactFactors | [{xxx}] | 配置该指标的相关影响因素(其他指标)。 见下文 | - |
| is_name | true/false | 是否是名称类型 | false |
| is_categorical | true/false | 是否是分类类型 | false |
| is_fake | true/false | 是否是假数据字段 | false |
| level | 字符串 | 只有在type为object的时候会存在,表达这个object的最细粒度为某一个level | - |
| constraints | {} | 配置该指标的约束条件,例如:该指标的取值范围。 | "constraints": {"enum": null, "unique": false, "required": true } |
| isArray | true/false | 是否是数组类型 | false |
| is_comparable | true/false | 是否可比较 | false |
| is_additive | true/false | 是否可加,设为false的话,在聚合的时候默认取平均值。 | false |
| granularity | year, quarter, month, day(默认), hour, minute, second | date类型的字段在前端展现粒度 | day |
| etl | etl的一种配置方式。在schema有很多字段的时候采用 见此页面 | ||
| hierarchy | 自由配置维度/分类 下钻 见此页面 | ||
| orderby | ASC/DESC | TopN的逻辑的时候,系统默认是倒序。此字段设为ASC后,TopN变为正序 | DESC |
| can_drilldown | true/false | 该字段是否参与下钻 | |
| pattern | 一个正则表达式 | 如果在提问的时候,搜索词里面有内容符合该正则表达式,则此字段可以被搜索出来 | |
| quantifier | 量词 | 提问者会用数字+该词进行结尾。例如【岁】 | |
| udf | 动态列。见下文 | ||
| wider_range | true/false | 只在使用clickhouse作为底层数据库时,在时间戳和日期时间类型生效。代表使用DateTime64格式。注:必须在创建时就指定,修改无效。 | |
| use_minus_on_mom | true/false | 这个指标的同环比计算用差值 | |
| valueTransformer | 一个函数见下文 | 可以在对这个字段做比较前对该字段做一定的改动 | |
| recommend_kpis | PredItem数组 | 在展示这个指标的时候,右侧可以替换掉同环比,展示其他相关的指标。 是一个数组,里面每一项是一个pred item | |
| enumMap | id映射 | 在直连场景底层字段是id,不想关联实体、也不想通过udf做修改,即可使用枚举映射实现。见下方#enumMap |
is_observation 的详细解释
在实际的数据场景中,经常有一类数据储存的是对一个指标的观测值/余额值。例如气温、库存、余额。此类数据在时间上不具备可加性。考虑如下一段数据:
| 日期 | 产品 | 库存件数 |
|---|---|---|
| 2023-01-01 | SKU001 | 100 |
| 2023-01-01 | SKU002 | 100 |
| 2023-01-02 | SKU001 | 200 |
| 2023-01-02 | SKU002 | 200 |
其中,库存件数是一个观测值。也就是说,在 2023-01-01,SKU001 的库存为 100。到了 2023-01-02,SKU001 的库存为 200(而不是增加了 200)。
那考虑如下提问: 2023 年 1 月份库存件数。
这个时候,我们应该计算的是所有2023-01-02的产品总库存件数,而不是整个 1 月份的所有数据加总。此时只要将库存件数这个属性标记上is_observation = true即可达成此效果。
注意:is_observation 功能如果开启,那么只要某一天有数据,必须保证所有维度都有数据,不然视为 0。 例如,2023-01-03,SKU001 的库存件数为 300。而 SKU002 的数据缺失。那么系统会认为 2023-01-03这个时间点SKU002 的库存件数为 0,而不是 2023-01-02 的 200。 注意:is_observation 功能如果开启,数据是类似快照的形式。比如库存一个月统计一次,那么每个月需要统一在一个时间点存储完整的库存数据。
ui 字段配置项
| 字段 | 可选值 | 解释 | 默认 |
|---|---|---|---|
| formatter | 0.0A | 此字段在简单模式中也能配置,就是数据格式对应的字段 | |
| representation | column/line/pie/bar/map | 该指标默认的图表显示方案 | |
| name | true/false | 前端把本字段作为名称展示 | |
| show_in_detail_only | true/false | 该字段是否参与前端ui展示 | |
| mask | maskWith/unmaskedStartDigits/unmaskedEndDigits/unmaskedStartCharacters/unmaskedEndCharacters | 该属性能够快速对数据进行脱敏。对于mask 的详细解释在下方 |
mask详细使用方式
"ui": {
"mask": {
"maskWith": "*",
"unmaskedStartDigits": 4,
"unmaskedEndDigits": 1,
"unmaskedStartCharacters": 4,
"unmaskedEndCharacters": 1
},
"copyable": true
}
其中:unmaskedStartDigits和unmaskedEndDigits,分别指代保留开头n位字符和结尾n位数字 unmaskedStartCharacters和unmaskedEndCharacters,分别指代保留开头n位字符和结尾n位字符 根据不同的字段类型选择对饮的类型配置,maskWith指代用某个符号做脱敏符号,copyable对应单元格数据是否可以复制 更多信息在 https://www.npmjs.com/package/maskdata 该网址处查看
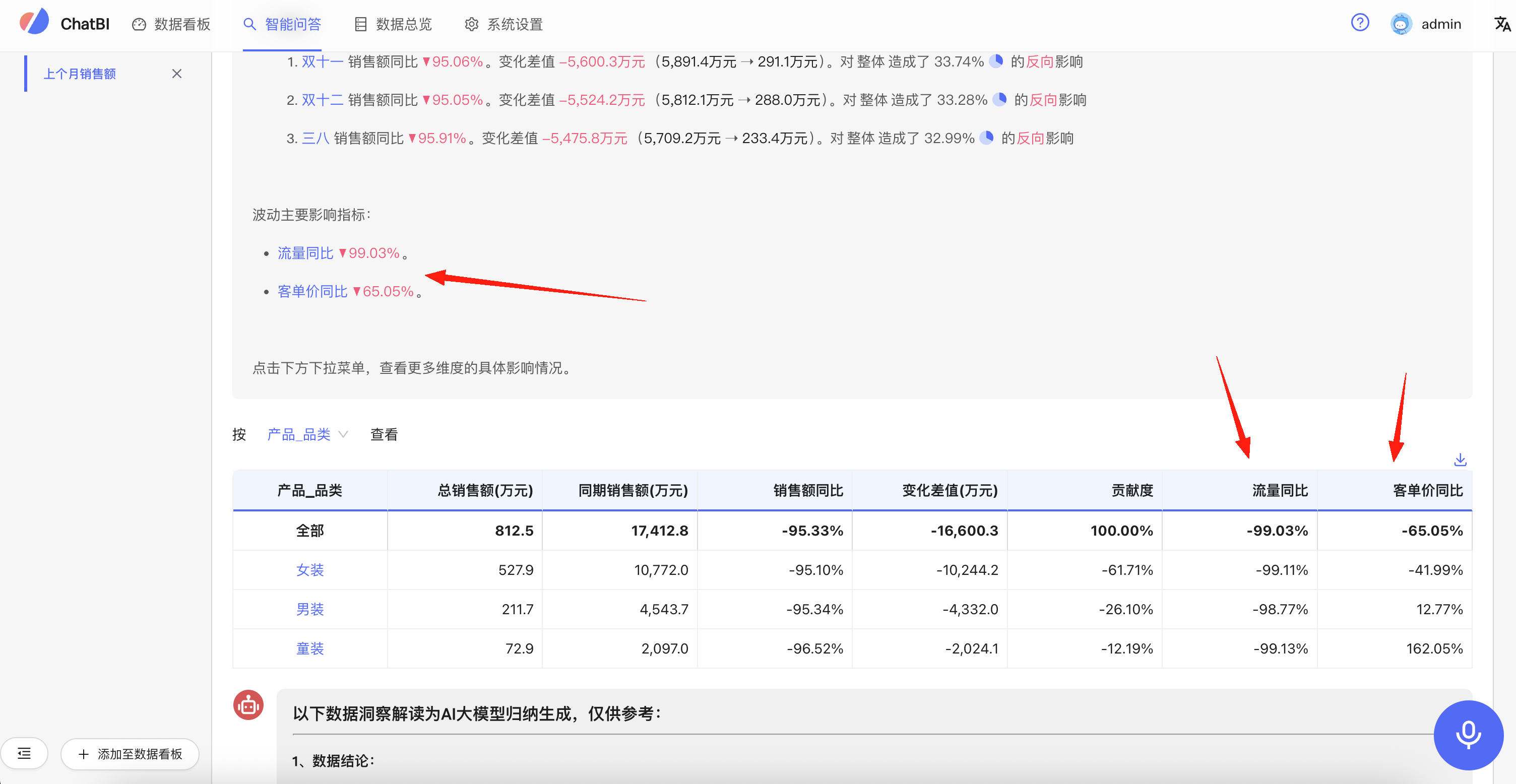
影响因素配置
有时候,指标和指标之间并没有明显的计算关系,但是两者有一定的业务关系。可以给一些指标配置相关的受影响指标。
例如:销售额受流量和客单价影响。那么我们可以在销售额的字段中,打开专家模式,找到销售额字段。配置impactFactors字段,格式为predItem的数组格式:
{
"name": "销售额",
"type": "currency",
"impactFactors": [
{
"schema": "visit",
"operator": "$sum",
"pred": "流量"
},
{
"operator": "客单价"
}
]
},
指标可以是另外一个schema的,就如流量指标。 指标可以是表中的某一列,也可以是自定义指标。 如客单价就是自定义指标。
如果要修改自定义指标和其他指标之间的影响因素关系,可以在指标编辑里面选择专家模式,同样放入impactFactors字段。
影响因素配置后,效果如下图所示:
动态列
如果有一个列可以通过其他列进行合并、计算所得,可以配置一个动态列,即时生成结果。
例如:有人员的出生日期列,那么人的现在的年龄就可以通过动态列来实现。
动态列的配饰方法为,加入一个udf字段,形式如下:
{
"udf": {
"sql": "year(now()) - year(出生日期字段)"
}
}
agg_key配置
如果目标表结构的销售额,是其中金额类型分类字段其中一个内容的金额加总
当一张表同时存储多个指标名称,且多个指标名称存储在同一列中作为分类,而非单独的指标列,例如费用、人数等不太相干的指标名称,他们出现在同一列中,在其后有对应的指标值列,存储对应的费用指标值和人数指标值
此时需要将指标名称列单独拉出作为实体,我们在该表专家模式的properties外添加agg_key配置(如下)
"agg_key": {
"key": "指标列名",
"value": "指标值列名"
},
"properties": [],
... ...
假设此时我们需要定义一个“花费金额”的指标,逻辑是指标列为“费用”的指标值列的和,可以在全局同义词中给“费用”配置上同义词“花费金额”
此时提问:“上个月的人数”,能得到指标列为“人数”对应的指标值的和,提问:“上个月的花费金额”,能得到指标列为“费用”对应的所有指标值的总和
can_combine_aggkey 配置
当一张表开启了agg_key的配置,但是数值列不止一列时,可以在其他的数值列字段中添加如下配置:
"can_combine_aggkey": true
假设一张财务表中同时存了"实际"和"预算","实际"绑定着对应的财务费项指标,如"收入","费用",可以通过在properties外部配置实际值为agg_key实现问收入就是费项为"收入"的实际值。 此时,在预算字段中添加上述配置,那么该列的概念就是收入预算
valueTransformer
可以在对这个字段写入where条件前对该字段做一定的改动
使用场景:用户生日类问题。 如:3月生日的用户有哪些?(甚至上半年/2季度等表达方式) 在建模中,为了让生日字段可以接受月份,生日字段需要是日期时间类型。但这样会造成3月份会被理解为当年的3月份。 在最后生成的SQL中,需要去掉年份信息。
对于以下Logicform:
{
"query": {
"生日": {
"$gte": "2024-03-01 00:00:00",
"$lte": "2024-03-31 23:59:59"
}
},
"schema": "vip"
}
使用valueTransformer前对应SQL:
SELECT * FROM vip
WHERE `birthday` >= "2024-03-01 00:00:00" AND `birthday` <= "2024-03-31 23:59:59"
使用valueTransformer后对应SQL:
SELECT * FROM vip
WHERE formatDateTime(birthday, '%m%d') >= formatDateTime("2024-03-01 00:00:00", '%m%d') AND formatDateTime(birthday, '%m%d') <= formatDateTime("2024-03-31 23:59:59", '%m%d')
以上是valueTransformer的效果,下文开始介绍valueTransformer的写法。
valueTransformer是一个函数(写完之后需要转成字符串存入schema json)。该函数接受两个参数,一个是比较符右侧的值,另外一个是一些帮助函数(含moment)。返回一段放进where条件的SQL,如:formatDateTime(birthday, '%m%d') >= formatDateTime("2024-03-01 00:00:00", '%m%d')
valueTransformer的案例如下:
"valueTransformer": "(value, {moment}) => {if (value.$gte) { this.birthday_gte = value.$gte; return `formatDateTime(birth, '%m%d') >= '${moment(value.$gte).format('MMDD')}'`;} else if(value.$lte) { if (moment(value.$lte).isLeapYear() && value.$lte.indexOf('02-28') > 0 && this.birthday_gte.indexOf('02-01') > 0) { value.$lte = value.$lte.replace('02-28', '02-29'); } return moment(value.$lte).isLeapYear() ? `formatDateTime(birth, '%m%d') <= '${moment(value.$lte).format('MMDD')}'` : `formatDateTime(birth, '%m%d') <= '${moment(value.$lte).format('MMDD')}' AND formatDateTime(birth, '%m%d') != '0229'`; }}"
enumMap
字段专家模式
"constraints": {
"enum": [
"男",
"女"
],
"enumMap": [
"1",
"2"
]
},
【实验性功能】自动抽取字段关键词
可以从一些商品名字、公司名字中,把一些关键词抽取出来。效果如下图所示,其中【关键词】列的数据是自动生成的。

配置方法如下,进入属性的专家模式,进行如下配置:
{
"name": "关键词",
"type": "tag",
"feature_extracted_from": [
"名称"
],
"rankOffset": -2
}
其中,name字段可以自定义。 type字段必须为标签(tag)类型。
核心是feature_extracted_from字段。 是一个数组。 里面填写要从哪一/几个字段抽取相关关键词。
最后,rankOffset字段是一个优先级,越小优先级越低。建议设为-2。这样这些关键词不会影响已有的概念。
要生成关键词,需要点击 重新学习所有表 。
注意⚠️:当数据量比较大的时候,可能要好几分钟才能成功抽取完成。
注意⚠️:和auto_syno的区别。 auto_syno是名称(name)类型,而feature_extracted_from是分类类型(category以及其数组形态tag)