数据源要求
本系统虽然可以通过etl工具进行任意的数据转换,但更规范的数据源,可以让本系统的实施工作事半功倍。此文档描述了什么样的数据源有助于加快本系统的实施。
目录
- 数据模型
- 数据中的指标要求
1. 数据模型
本系统在三范式建模或雪花模型(维度建模)下,会有比较好的问答效果,会降低etl工作量。 其中,三范式建模的方式效果最好。建模案例如下所示:
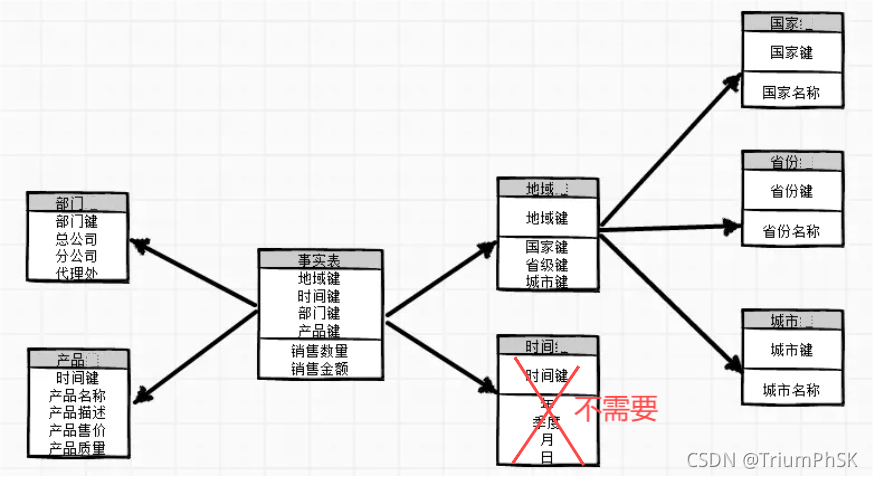
关于三范式建模或雪花模型相关文章,可点此查看
以下是除了上述两种建模方式本身的要点之外的其他要点。
要点一:一个概念尽量只存在于一处
举例:如北京、上海这些地理位置。 可以存到一张地理位置表中。 其他所有表通过外键关联到此表。 而不是每一张表中都有独立的地理位置字段。
要点二:数据尽量清洗干净
举例:如果企业自身数据里面有一家子公司的公司名叫【北京】。那么会和地理位置的【北京】相冲突。在使用者问:北京今年业绩的时候,系统会有歧义。 虽然本系统会出来一个2选1,二次询问用户想要问的是哪个北京,但会对用户体验造成一定程度的困扰。
数据中的指标要求
数据中的指标指的是数据表中那些可计算、需要聚合的值。例如销售额、收入等。
对于指标的第一个要求是具备可加性,并且在各维度上加总 = 全体加总。
在这里举两个反面例子。
- 反面例子一:
数据库里面有1月份~12月份每个月的销售目标数据。另外还有一行是全年的销售目标数据。 并且1月份~12月份每个月的销售目标数据加总不等于全年目标。
所以要求在问答的时候,问到月份的时候去查月级别的数据,问到年份的时候去查年级别的数据。
这样的数据构成虽然本系统可以支持,但是会大幅加大实施难度和工作量。
- 反面例子二:
例如数据库里面有一个叫近视率的指标。数据记录了每年在每个省份的近视率的值。 并且还有一行是每一年全国的近视率的值。
在这种数据情况下,类似于长三角的近视率此类问题是无法回答的。 正确做法应该是同时保存分子和分母,即每年在每个省份的近视人数以及每年在每个省份的总人数。 近视率则使用本系统的自定义指标功能配置动态公式。
注:本系统也支持一些非可加性的指标。例如观测类指标(又叫余额类指标)。详情请搜索is_observation参数。
对于指标的第二个要求是不要带上维度。
观察以下表格:
| 日期 | 公司 | 总收入 | 主渠道收入 | 副渠道收入 |
|---|---|---|---|---|
| 2021 | 公司A | 100 | 90 | 10 |
| 2022 | 公司B | 100 | 90 | 10 |
在此数据结构下,其实主渠道收入 + 副渠道收入 = 总收入。其中主渠道和副渠道,其实是数据维度,而不是指标的一部分。 在这个场景下,其实就只有一个指标,叫做收入。主渠道和副渠道应该是公司具体某一个渠道的分类属性。所以表结构需要改造为:
渠道表:
| ID | 名称 | 分类 |
|---|---|---|
| 001 | 渠道A | 主 |
| 002 | 渠道B | 副 |
收入表:
| 日期 | 公司 | 渠道 | 收入 |
|---|---|---|---|
| 2021 | 公司A | 001 | 90 |
| 2021 | 公司A | 002 | 10 |
| 2022 | 公司B | 001 | 90 |
| 2022 | 公司B | 002 | 10 |